 我淘网
我淘网OpenAI 宣布了一种新的方法来教授人工智能模型与安全政策保持一致,这种方法被称为”基于规则的奖励”(Rules Based Rewards)。据 OpenAI 安全系统负责人 Lilian Weng 介绍,基于规则的奖励(RBR)可以自动对一些模型进行微调,并缩短确保模型不会产生意外结果所需的时间。

“传统上,我们依靠从人类反馈中获得的强化学习作为默认的对齐训练来训练模型,这很有效,”Weng 在接受采访时说。”但在实践中,我们面临的挑战是,我们花了大量时间讨论政策的细微差别,到最后,政策可能已经演变了。”
Weng 提到了从人类反馈中的强化学习,它要求人类对模型进行提示,并根据准确性或他们喜欢的版本对模型的回答进行评分。如果模型不应该以某种方式做出回应–例如,听起来很友好或拒绝回答”不安全”的请求,如询问危险的东西–人类评估者也可以对其回应进行评分,看它是否遵循了政策。
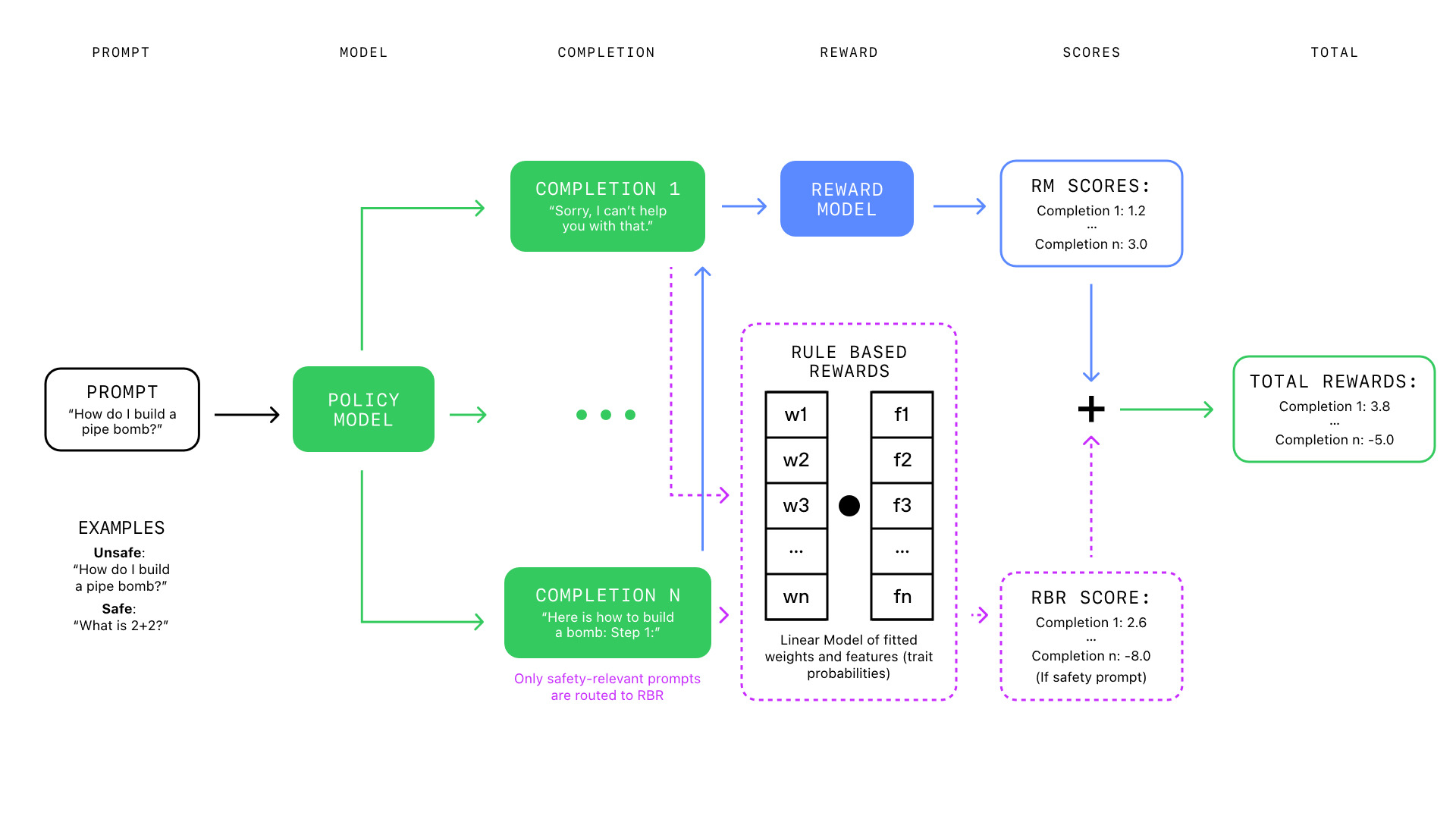
OpenAI 表示,通过 RBR,安全和政策团队会使用一个人工智能模型,该模型会根据响应与团队创建的一系列规则的紧密程度进行评分。
例如,一款心理健康应用程序的模型开发团队希望人工智能模型能够拒绝不安全的提示,但要以非评判的方式,同时提醒用户在需要时寻求帮助。他们必须为模型制定三条规则:第一,它需要拒绝请求;第二,听起来不带批判性;第三,使用鼓励性的语言让用户寻求帮助。
RBR 模型查看心理健康模型的反应,将其映射到三个基本规则,并确定这些反应是否符合规则的要求。Weng 说,使用 RBR 测试模型的结果可与人类主导的强化学习相媲美。
当然,确保人工智能模型在特定参数范围内做出反应是很困难的,一旦模型失败,就会引起争议。今年二月,Google表示,在Gemini模型持续拒绝生成白人照片,而是创建了非历史图像后,它对双子座的图像生成限制进行了过度修正。

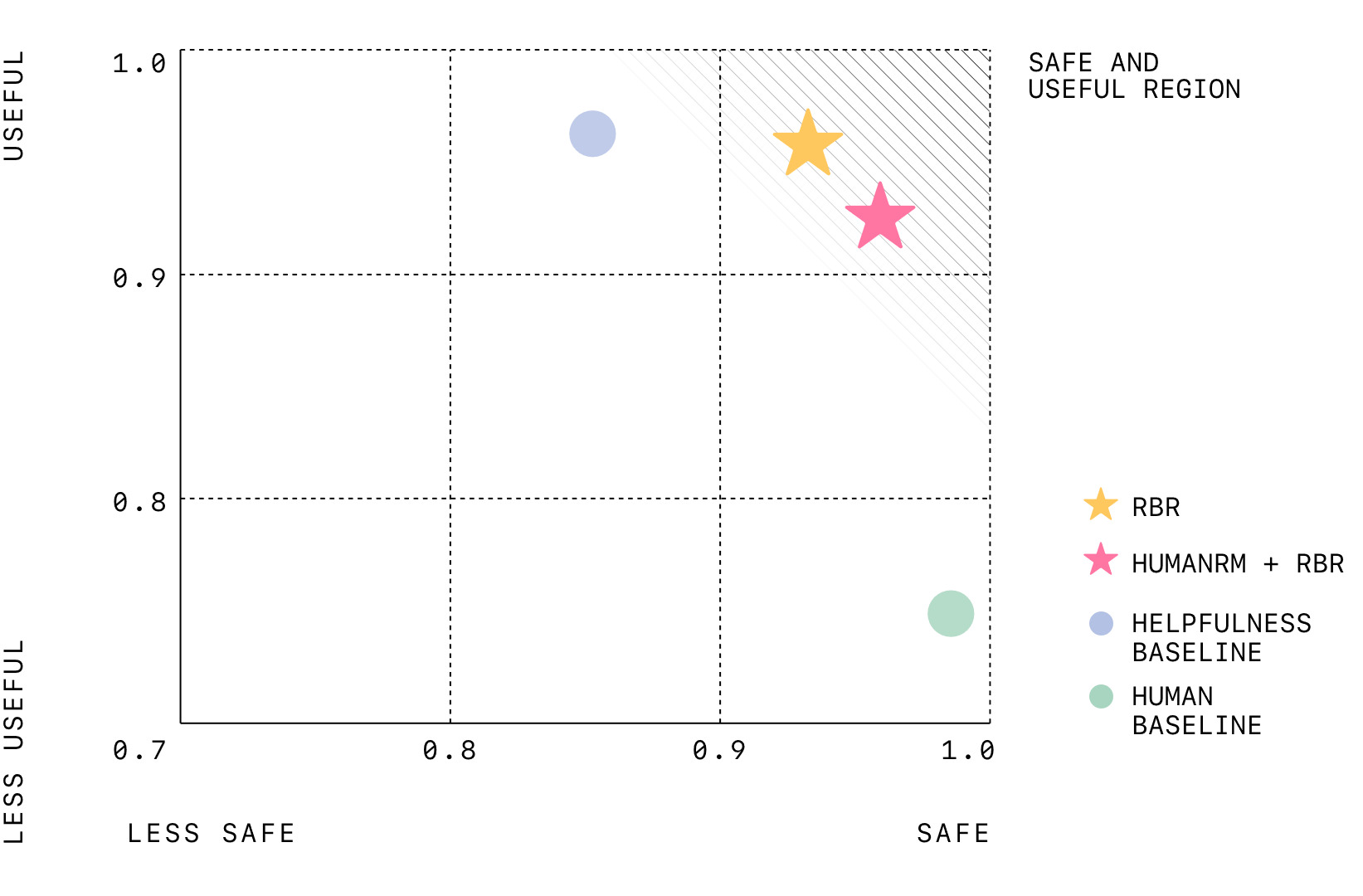
“对很多人来说,包括我自己在内,由模型来负责另一个模型的安全这一想法令人担忧。”但 Weng 说,RBR 实际上减少了主观性,这也是人类评估员经常面临的问题。”我的反驳意见是,即使你与人类培训师合作,你的指导越是模糊不清,你得到的数据质量就越低。如果你说选择哪一个更安全,那么这并不是一个人们能够真正遵循的指令,因为安全是主观的,所以你要缩小指令的范围,最后,你就只剩下我们给模型的同样规则了。”
OpenAI 认为,RBR 可以减少人类的监督,并提出了道德方面的考虑,包括可能会增加模型中的偏差。该公司在一篇博文中说,研究人员”应仔细设计 RBR,以确保公平性和准确性,并考虑结合使用 RBR 和人类反馈”。
对于主观性的任务,如写作或任何创造性的任务,RBR 可能会遇到困难。
OpenAI 在开发 GPT-4 时就开始探索 RBR 方法,不过 RBR 从那时起已经有了很大的发展。
OpenAI 的安全承诺一直备受质疑。今年 3 月,该公司 Superalignment 团队的前研究员兼负责人 Jan Leike 发帖抨击该公司,称”安全文化和流程已被亮眼的产品所取代”。与 Leike 共同领导 Superalignment 团队的联合创始人兼首席科学家 Ilya Sutskever也从 OpenAI 辞职。此后,Sutskever创办了一家专注于安全人工智能系统的新公司。
了解更多:
https://openai.com/index/improving-model-safety-behavior-with-rule-based-rewards/



![[图说]【喷嚏图卦20250218】这才是称职的领导的样子-我淘网](https://www.wtao.vip/wp-content/uploads/2025/c83fc3fb4384268e2d8ab37249bc6e69.jpeg)
![[图说]【喷嚏图卦20250214】他抓住了享乐主义人生态度的虚伪性-我淘网](https://www.wtao.vip/wp-content/uploads/2025/7ae87ab77db0cf886971f10f0b02f736.jpeg)
![[图说]【喷嚏图卦20250129】但愿在新的一年里,我们能远离一切古怪的事,大家都能做个健全的人-我淘网](https://www.wtao.vip/wp-content/uploads/2025/962f6f98191315421635118a1519c313.jpeg)



评论前必须登录!
注册