 我淘网
我淘网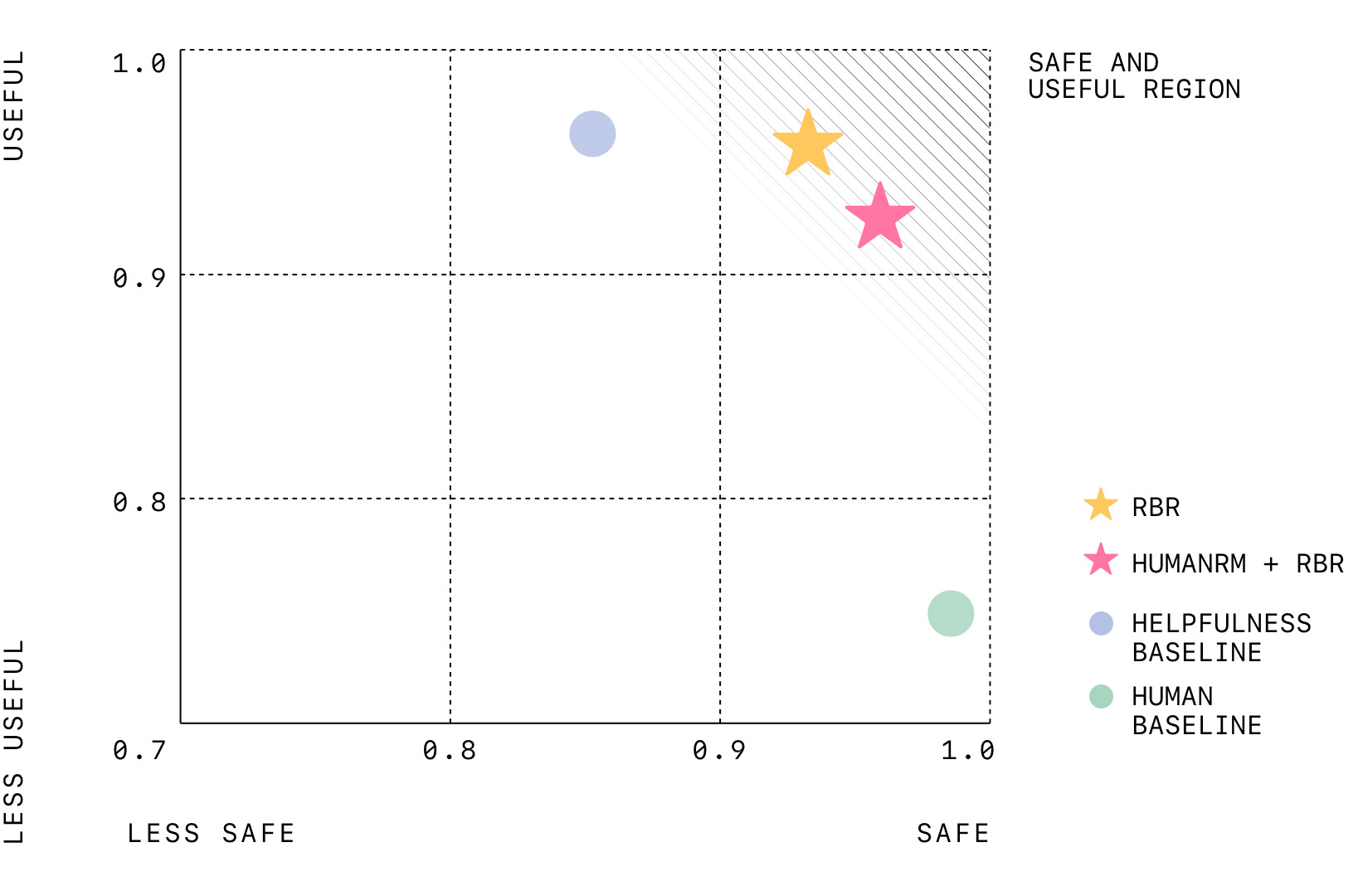
OpenAI开发了一种新方法来教授AI模型与安全政策保持一致
OpenAI 宣布了一种新的方法来教授人工智能模型与安全政策保持一致,这种方法被称为”基于规则的奖励”(Rules Based Rewards)。据 OpenAI 安全系统负责人 Lilian Weng 介绍,基于规...
OpenAI 宣布了一种新的方法来教授人工智能模型与安全政策保持一致,这种方法被称为”基于规则的奖励”(Rules Based Rewards)。据 OpenAI 安全系统负责人 Lilian Weng 介绍,基于规...
 坎坷de卖菜仔
坎坷de卖菜仔